Business Goal: As an owner of MuShu Bike Rental CO. in New York. I want to know how many bicycles will be rented on any given day based on daily temperature, humidity and wind speed. Can you help MuShu Bike Rental CO. to predict the number of daily rentals?
How to get the dataset?
Let’s solve this problem using SVR - Support Vector Regression.
Before we begin, let’s see the key terms that will be used.
Key terms
- Kernel
A fancy word for the function used to map a lower dimension data into higher dimension data.
- Hyper Plane
This is a line that helps us predict the target values.
- Boundary Line
There are two boundary lines which separate the classes. The support vectors can be on the boundary line or outside the boundary line.
- Support Vectors
Support vectors are the data points which are closest to the boundary line.
What is a SVR model?
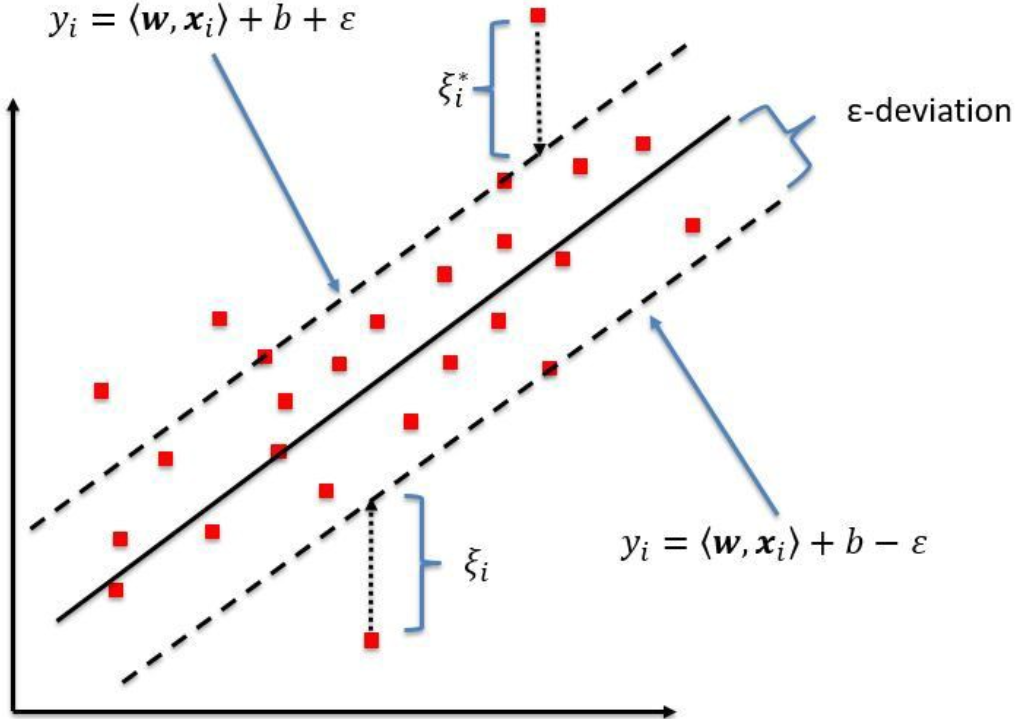
In Simple/multiple regression we try to minimize the errors while in SVR, we try to fit the error within a threshold.
Blue Line: Hyper Plane | Red Line: Boundary lines

Looking at the above figure, our goal is to have the data points inside the boundary lines and hyperplane with the maximum number of data points.
What is “Boundary again?
The red lines that you see in the diagram above are called boundary lines. These lines are at equidistant from a hyper plane (Blue line). So basically, if one boundary line is at distance “e” distance from a hyper plane the other would be at distance of "-e”.
In mathematical equation.
If the hyper plane line is a straight line going through Y-AXIS and represented as
mX + C =0
Then the equation of boundary lines can be represented as
mX + C = e
mx +C = -e
The final equation of SVR can be represented as
e≤ y-mx-c ≤+e
To summarize: The goal so far is to find the distance value e which is equidistant from
hyper planeline with the maximum data points OR that they are inside theBoundary line.
Exploring the dataset
|
|
|
|
| temp | humidity | windspeed | bike_rent_count | |
|---|---|---|---|---|
| 0 | 9.02 | 80 | 0.0000 | 40 |
| 1 | 9.02 | 80 | 0.0000 | 32 |
| 2 | 9.84 | 75 | 0.0000 | 13 |
| 3 | 9.84 | 75 | 0.0000 | 1 |
| 4 | 9.84 | 75 | 6.0032 | 1 |
|
|
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| temp | 9801.0 | 20.230348 | 7.791740 | 0.82 | 13.9400 | 20.500 | 26.2400 | 41.0000 |
| humidity | 9801.0 | 61.903989 | 19.293371 | 0.00 | 47.0000 | 62.000 | 78.0000 | 100.0000 |
| windspeed | 9801.0 | 12.836534 | 8.177168 | 0.00 | 7.0015 | 12.998 | 16.9979 | 56.9969 |
| bike_rent_count | 9801.0 | 191.334864 | 181.048534 | 1.00 | 42.0000 | 145.000 | 283.0000 | 977.0000 |
|
|
Index(['temp', 'humidity', 'windspeed', 'bike_rent_count'], dtype='object')
|
|
|
|
|
|
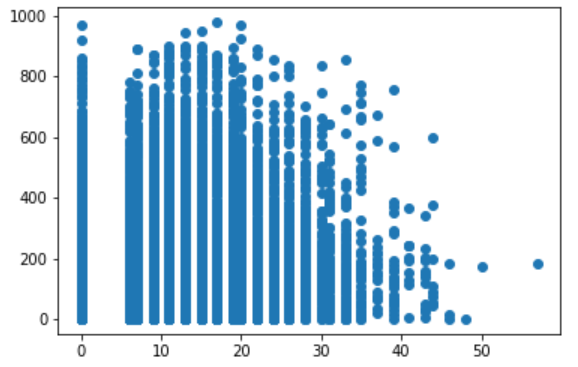
Summary
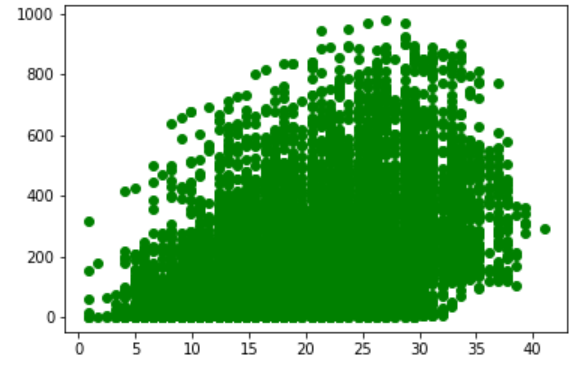
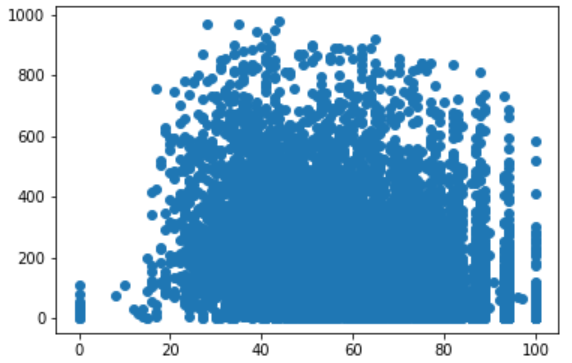
Based on data description and histogram plot.
- Temp Range = 0 to 41
- Humidity Range = 0 to 100
- Windspeed = 0 to 57
|
|
| temp | humidity | windspeed | bike_rent_count | |
|---|---|---|---|---|
| temp | 1.000000 | -0.060524 | -0.020792 | 0.393114 |
| humidity | -0.060524 | 1.000000 | -0.317602 | -0.312835 |
| windspeed | -0.020792 | -0.317602 | 1.000000 | 0.096836 |
| bike_rent_count | 0.393114 | -0.312835 | 0.096836 | 1.000000 |
Summary
- Looking at the correlation matrix, we see that there is a positive relationship between
temperatureandbike_rent_count Humidityhas a negative effect onbike_rent_count. Higher the humidity, lower the number of rentalsWindspeedhas little effect onbike_rent_count.
Looking at the correlation matrix, it confirms the visuals that bike count rental has a weak correlation with all of the 3 variables.
What does a weak correlation mean?
It means that the equation of the model that we are going to plot is probably not going to give very accurate results. However, the goal of this post is to show you how to implement SVR.
So Let’s bring out our template from our first post on data pre-processing.
Step 1: Let’s break the data into Dependent and Independent variable
|
|
Step 2 : Break the data into train and test set
|
|
Step 3: Feature scaling. This step is required here beacause SVR library does not do feature scaling.
|
|
Step 4: Create a Regressor and fit the model
|
|
SVR(C=1.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1,
gamma='auto_deprecated', kernel='linear', max_iter=-1, shrinking=True,
tol=0.001, verbose=False)
In the above code, we are using the SVR class for fitting the model.
SVR(
[“kernel=‘rbf’”, ‘degree=3’, “gamma=‘auto_deprecated’”, ‘coef0=0.0’, ’tol=0.001’, ‘C=1.0’, ’epsilon=0.1’, ‘shrinking=True’, ‘cache_size=200’, ‘verbose=False’, ‘max_iter=-1’],
)
The SVR model that we are using provides 4 types of Kernel - rbf, linear, poly, sigmoid. In our case, we are using linear since data appears to be linear based on visualizations. Another interesting attribute is verbose, which when set to true will show you the default values used of other attributes.
Step 5: Predict the bike count based on test data
|
|
Step 6: Check the model effeciency
|
|
Train Score: 0.19926232721567205
Test Score: 0.2082800818663224
As mentioned earlier, since the correlation is weak, we can see that our model is extremely weak. One thing to note here is that I downloaded this random dataset from some website. So when I was working on SVR, I was not sure if the data is true or not.
Let’s try the tweaking SVR model a little to see if we can do better.
|
|
Train Score: 0.25167703525198526
Test Score: 0.2484248213345378
So after playing around with different option and values, you will see that if you use poly or polynomial kernel, I was able to push the model prediction to 25.xx%.
So that’s it for this series. Try a different dataset, probably get one from the Multiple Linear regression about 50_Startups and predict using linear kernel.
In the next series, we will learn about our first ever classification model - Decision Trees. Till then happy Happy hyper-planing